Au sein d'un langage de programmation les caractères sont représentés (si on simplifie les choses) sous forme de nombres selon ce qu'on appelle le code ASCII (American Standard Code for Information Interchange). Le tableau ci-dessous indique cette correspondance, ce qui nous intéresse étant les colonnes "Dec" (code décimal) et "Char" (caractère associé).
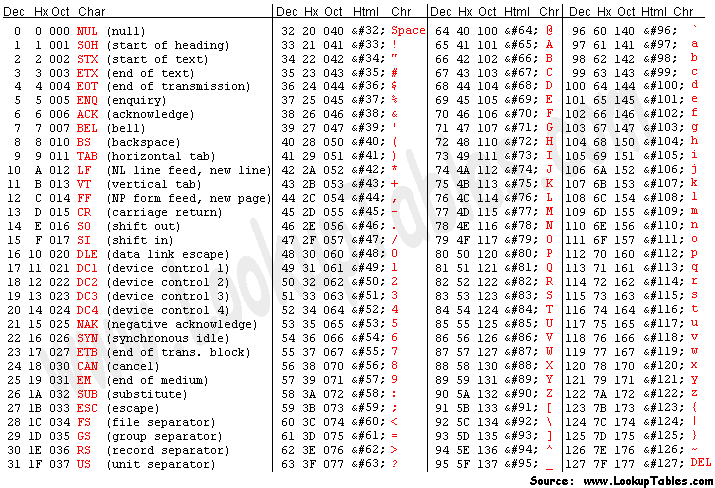
La plupart des 31 premiers caractères sont ce qu'on appelle des "caractères de contrôle", on ne s'y intéressera pas. Remarquez tout le même qu'ils contiennent la tabulation (Dec = 9) ou les retours à la ligne (Dec = 10 par exemple).
Ce qui est intéressant c'est qu'il est possible de convertir un caractère vers son code ASCII, et inversement.
Caractère -> code
caractere = "U" code = ord(caractere) print(code)
85
Code -> Caractère
code = 111 caractere = chr(code) print(caractere)
o
Encodage réel
En Python, les chaînes de caractères sont en réalité codées en UTF-8, un code (ou encodage) plus général que l'ASCII et qui permet de représenter plus de caractères, par exemples les caractères chinois. En UTF-8, Les caractères d'indices inférieurs à 128 sont exactement les mêmes que en ASCII : le tableau ci-dessus fonctionne donc.
Afficher la liste des caractères
Ci-dessous, vous trouverez un petit code permettant d'afficher la liste des caractères existants avec leur code associé. Les caractères d'indice inférieur à 32 sont affichés sous la forme d'un espace car les afficher normalement poserait des problèmes, étant donné qu'ils ont un sens spécial. Le code peut faire appel à des éléments de syntaxe que vous n'avez pas encore vu, il est simplement donné à titre d'exemple.
# Caractères 0 à 1023
for bloc in range(8):
for lig in range(16):
for col in range(8):
code = 128 * bloc + 16 * col + lig
caractere = chr(code)
if code < 32:
caractere = " "
print("{:04d} {} ".format(code, caractere), end = "")
print()
print()